
|
|
|
webalizerでアクセス解析
|
Webアクセス解析とはWebalizer日本語版の導入Webalizerの基本設定httpdログの構造を理解するApacheでログを振り分ける検索文字列の日本語化統計データの見方について解析データの最適化と分析法解析スケジュールの設定デフォルト以外のアクセス解析 |
検索文字列の「文字化け」を解消する
Webalizer
は比較的不具合が少ない
アプリケーション
ですし、適当に
インストール
を行えば日本語でタイトルを表示することもできます。
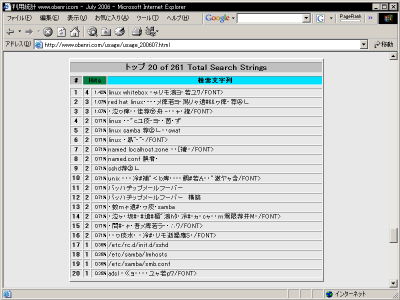
ところが一つとても困ることがあります。 それは "Total Search Strings" の解析結果、つまり「どういった言葉で検索されたページからアクセスされたのか」という情報が文字化けしてしまうことです。 実は、Googleを始めとする検索サイトの多くは日本語、中国語などの2 バイト 文字で検索が行われるとき、他の言語との整合性をとるために UTF-8 に 文字コードセット を変換してから検索を行うようになっています。 そしてその検索結果はそのまま ログ データの リファラー の位置に記録されるわけですが、Webalizer自身はこれを自分自身の表示文字セットである EUC に変換する機能を持っていないため、UTF-8のまま表示してしまうために「文字化け」となってしまうわけです。 この "Total Search Strings" は、この コンテンツ がどういう検索語で「引っ掛けられているのか」を知る上でとても重要な解析データなので、これはなんとか対策し、きちんと検索語が表示できるようにしたいものです。 要は、UTF-8に変換されている文字をEUCに変換し直せば良いわけですから、 1.ログファイル中でUTF-8に変換されている文字列をEUCに変換した別のログファイルを作成し、そのログファイルに対してWebalizerによる解析処理を行う。 2.Webalizerでよる解析処理で出力された HTML ファイルの中でUTF-8に変換されている文字列をEUCに変換してHTMLファイルを作り直す。 という二つの方法が考えられます。 結果としてはどちらも同じになるはずですが、膨大な容量になる可能性のあるログファイルに対して直接変換処理を行う1.よりも、既に解析が終わってデータ量が小さくなっている解析結果に対して処理を行う2.のほうが ホスト機 への負担も小さく、処理にかかる時間も少ないので、ここでは2.の方法について解説します。 文字コードの変換には日本語の扱いに長けた Perl を利用し、ファイル操作にはファイル処理に長けた bash を利用し、それぞれの シェル スクリプト を組み合わせて変換システムを作ります。作業は、 1.文字コード変換に必要なPerlのモジュールを インストール する。 2.文字コード変換用のシェルスクリプトを作成する。 3.Webalizer実行用のシェルスクリプトを作成する。 4.作成した3.を crond で自動実行できるように設定する。 という手順で行います。
|
|||||||||
日本語処理モジュール"Jcode.pm"のインストールJcode.pm は、 Perl を使って日本語の様々な文字コードを相互に変換することを可能にするモジュールです。 |
||||||||||
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
 お便利サーバー.com
検索ロボット
お便利サーバー.com
検索ロボット
|
このモジュールは今回行う Webalizer の文字化け対策だけではなく、 Webサーバー 上で CGI を利用する際も利用できますから、ぜひ インストール しておきましょう。 Jcode.pmは、 "CPAN" という Perl のライブラリ サーバー から、使用中のバージョンのPerlに対応するものを簡単にインストールすることができます。
まず、
サブネット
内の適当な
クライアント機
から
SSHクライアント
で
構築中のLinuxサーバー
に
ログイン
します
|
|||||||||
|
CPAN
は結構接続が切れやすいので、接続が怪しい状況(のような)メッセージが表示されるときは
Ctrl+c
で操作を中断し、最初からやり直してください。
なお、このとんでもなく面倒な接続作業が必要なのは最初の一回だけです。次からはすぐ "cpan>" が表示されるようになります。 安心してください。 また、既に
などで一度CPANの接続設定を済ませている場合は、
"perl -MCPAN -e shell"
を実行するとすぐにCPANを利用できる状態になります。
|
それから su コマンド で アカウント を "root" に変更し、以下のようにコマンドを実行して接続設定を行います。 なお、以下はWBEL3での接続設定の際のメッセージですが、これはサーバーの構成により異なる場合があります。
"cpan>" が表示されたら接続完了です。 引き続き次のようにタイプして Jcode.pm のインストールを行ってください。 通信環境などによっては数分以上かかる場合がありますので、気長に待ちましょう。
以上で Jcode.pm のインストールは完了しました。
|
|||||||||
UTF-8→EUCの変換スクリプトの作成インストールした Jcode.pm を用いて、 |
||||||||||
|
このシェルスクリプトの内容についての説明は、このコンテンツでは割愛します。
Perlのスクリプトについては非常に多くの解説書がありますので、興味のある方は勉強してみてください。 |
といっても、以下のようにスクリプトはたったの10行です。
この内容のテキストファイルを 構築中のLinuxサーバー 上の適当な場所に実行形式で保存すれば良いのですが、タイプするのが面倒という方は、以下のリンク を開いてコピー&ペーストするか、 ダウンロード して名前を変更し、 FTPクライアント などから サーバー に アップロード してください。
このスクリプトは汎用性がありますから、
パス
が通っているディレクトリ
|
|||||||||
| ファイル名の末尾が ".pl" になっているのは、これがPerlのスクリプトファイルであることを表すための「作法」のようなものだと思ってください。 |
ここではユーザーが作成した実行プログラムの格納場所として準備されている "/usr/local/bin" 以下に "u_e_conv.pl" というファイル名で保存するものとします。
ファイルを保存したら、かならず実行属性を与えてください
作成が終わったら、スクリプトが正しく動作するかどうかをテストしてみましょう。 以下のようにタイプして、UTF-8の文字列"%E6%A1%9C"のテストファイルを作成し、 "u_e_conv.pl" を実行します。
このように 「桜」 と出力されればOKです。 もしうまくいかないときは、スクリプトの内容のどこかに誤りがあるかもしれませんのでチェックしてください。
|
|||||||||
Webalizer実行用シェルスクリプトの作成Webalizer は デフォルト で "/var/www/usage/" 以下にいくつかの HTML ファイルを出力します。 要はこれらのファイルの中に含まれる UTF-8 の部分を EUC に置き換えれば良いということになります。 そこで、 |
||||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
1.通常どおりのWebalizerのアクセス解析処理を実行する。 2.得られた任意の.htmlファイルに対して "/usr/local/bin/u_e_conv.pl" を用いて同名の.tempという文字コード変換済みファイルを作成し、オリジナルの.htmlファイルと置き換える。 3. カレント ディレクトリ内の.htmlがなくなるまで2.の処理を繰り返す。 このシェルスクリプトでは、 文字列操作は Perl のシェルスクリプトである "/usr/local/bin/u_e_conv.pl" に任せてしまいますから、実際に行うのはファイル操作に過ぎません。従ってここではファイル操作に長けた bash を用いてシェルスクリプトを作成します。 |
|||||||||
|
汎用性を高めるため、このシェルスクリプトはカレントディレクトリを移動して実行するように作られています。
従って記述する コマンド はすべて 絶対パス 表記になっています。 コマンドのパスは which コマンドで調べることができます。 |
内容は以下のとおりです。
この内容のテキストファイルを 構築中のLinuxサーバー 上の適当な場所に実行形式で保存すれば良いのですが、タイプするのが面倒という方は、以下のリンク を開いてコピー&ペーストするか、 ダウンロード して FTPクライアント などから サーバー に アップロード してください。 |
|||||||||
| ファイル名の末尾が ".bash" になっているのは、これがbashのスクリプトファイルであることを表すための「作法」のようなものだと思ってください。 |
ここでは "u_e_conv.pl" と同じく、ユーザーが作成した実行プログラムの格納場所として準備されている "/usr/local/bin" 以下に "webalizer_def.bash" というファイル名で保存するものとします。 以下、このシェルスクリプトの内容について説明します。 |
|||||||||
|
|
1行目は使用するシェルの指定です。 2行目は cd コマンド によるカレントディレクトリの移動です。
そして3行目でWebalizerを実行しますが、
"-c"
は
「後に記述したファイルを設定ファイルとして指定する」
というオプションです
Webalizerはデフォルトでは "/etc/webalizer.conf" を参照しますから、この設定は一見余計なもののように思えます。 実はWebalizerは最優先で "/etc/webalizer.conf" を参照する訳ではなく、 、実行時のカレントディレクトリに同名のファイルが存在する場合にはこれを優先して参照するようになっています。 つまりこのオプションは、Webalizerが設定ファイルを間違えないようにするためのものと考えてください。
また、その後ろの
"> /dev/null"
は
「ヌルデバイスにリダイレクト出力
Webalizerは解析するログデータが大きすぎるケースなどで、比較的頻繁に「大勢に影響のないエラー」を出しますから、こういう処理を行っておくほうが煩わしくありません。 どうしてもエラー出力を保存しておきたい場合には、この部分を、
と設定しておけば常に最新のエラーメッセージだけが "/var/www/usage/error.msg" に記録されることになります。累積的に記録しておきたいときは
とすると良いでしょう。 |
|||||||||
|
一般的な他のプログラミング言語にも同じようなforループ構文はありますが、これらが「特定回数のループ」を行うためのものであるのに対し、bashなどのシェルスクリプトで用いるforループは、「条件に一致するすべてのファイルの処理が終わるまで」という処理を担います。
シェルスクリプトが「ファイル操作に特化している」というのは、こういう部分を指します。 |
4行目以降はbashでシェルスクリプトを作成するときに利用されるループ構文で、
のように記述し、[ファイルリスト]の条件に一致するファイルすべてに対し、特定の[ファイルリスト]名を[識別子]として do〜done の処理を実行します。 冒頭と説明は重複しますが、 "/var/www/usage/" 中のすべての "xxxx.html" に対して、 1. "/usr/local/bin/u_e_conv.pl" で文字コード変換したファイル "xxxx.html.temp" をオリジナルと同じディレクトリに作成する。 2. "xxxx.html.temp" を "xxxx.html" に改名してオリジナルに上書きする。 という処理を行うというわけです。 ファイルを作成したら、これにも忘れずに実行属性を与えてください。
以上で "Total Search Strings" の文字化けを修正するシェルスクリプトの準備が終わりました。
|
|||||||||
シェルスクリプトの動作確認と自動実行の登録では早速 シェル スクリプト "webalizer_def.bash" を実行してみましょう。 方法は root アカウント からシェル プロンプト で "webalizer_def.bash" を実行するだけです。
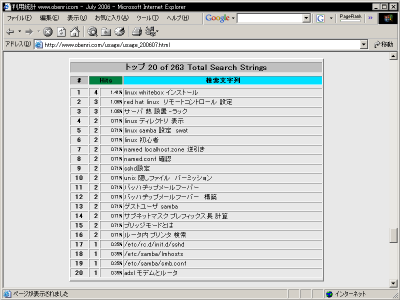
処理が終わったら、同じように Webブラウザ でアクセス解析結果の "Total Search Strings" を表示させてみてください。 以下のように文字化けは 比較的 きちんと解消されているはずです。 ただしご覧のとおり一部怪しい部分も残っています。 これは主に複数の検索語を組み合わせて検索が行われた場合に、 UTF-8 に変換された部分とそうでない部分との境界が曖昧になってしまうために起こる現象だと思われますが、今回説明した方法ではこれが限度ですので我慢するより他はないでしょう。 さて、ここでもう一つ忘れてはいけない作業があります。自動実行登録のやり直しです。 デフォルト の Webalizer は、 crond によって一日一回実行されるようになっています。
具体的には、実行ファイル
"webalizer"
を呼び出すシェルスクリプトが
"/etc/cron.daily/"
以下に
"00webalizer"
として保存されており、
"/etc/crontab"
中の
"run-parts"
によって実行されるようになっています
もちろんこの "00webalizer" が実行されてしまうとまた文字化けを起こしたアクセス解析結果が出力されてしまいますので、これを "webalizer_def.bash" と入れ替えてしまいましょう。
これで常に "Total Search Strings" はほぼ正しく変換された状態で閲覧できるようになりました。
なお、Webalizerのプログラムの実行スケジュールについては、
|






|
|
Apacheでログを振り分ける
<<Previous
|
Next>>
統計データの見方について
|
| このサイトは既に更新を終了していますが、今のところ店じまいの予定はありません。 リンクフリー ですので、趣味や勉強のためでしたら、引用、転用、コピー、朗読、その他OKです。このサイトへのリンクについては こちら をご覧ください。 |

|
| ”Linux”は、Linus Torvalds 氏の各国における登録商標です。”Red Hat”及びRed Hatのロゴおよび Red Hat をベースとしたすべての商標とロゴは、各国におけるRed Hat, Inc. 社の商標または登録商標です。その他のプログラム名、システム名、製品名などは各メーカー、ベンダの各国における登録商標又は商標です。 |

|