
|
|
|
webalizerでアクセス解析
|
Webアクセス解析とはWebalizer日本語版の導入Webalizerの基本設定httpdログの構造を理解するApacheでログを振り分ける検索文字列の日本語化統計データの見方について解析データの最適化と分析法解析スケジュールの設定デフォルト以外のアクセス解析 |
Apacheのログファイルについて
Apache
の設定のセクションの中で
ログ
ファイルの出力
ただ、Webalizerは特定のログデータを完全に除外して処理をするような仕様にはなっていないため、Webalizerで処理を行う前に 「統計に全く必要のないログデータ」 はログファイルから除外しておく必要があります。 その除外の方法については、 1.Webalizerの実行の前に適当な処理を行って不要なログデータを取り除く。 2.Apacheの機能を使って最初から不要なログデータを取り除いてデータを収集する。 という二通りの方法がありますが、ここでは面倒なテキスト処理用の シェル スクリプト を作成する必要のない 2. の方法について解説します。
ログファイルの形式と構造についてログファイルの振り分けの設定の説明の前に、まずはログファイルの構造について説明しましょう。 Apache が出力する ログ データは、一つのアクセスについて一行で テキスト 出力され、ログファイルの末尾に追加される形で蓄積されていきます。 試しに、このコンテンツのログファイルの中身を一部覗いて見ましょう。 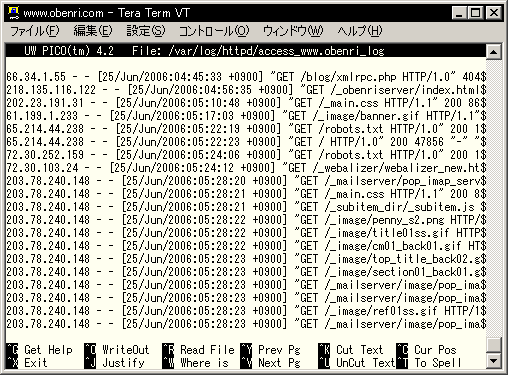
httpdのログファイルの例 初めてご覧になる方でも、一番左がアクセス元の IPアドレス 、次がそのアクセス時刻、そしてアクセス元が要求したファイル名、という具合に並んでいることは容易に想像できるはずです。 |
||||||||
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
 お便利サーバー.com
検索ロボット
お便利サーバー.com
検索ロボット
|
実際にはログデータはもっと長く、更に多くの情報が画面のずっと右側まで続いていますが、情報は順序正しく形式通りに並んでいます。 Apacheが一般的に出力するログの形式には "common" 形式と "combined" 形式があります。 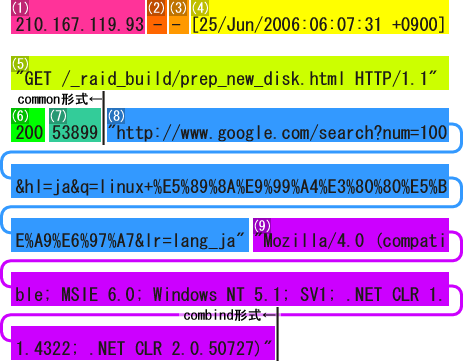
httpdログデータの例 図のように、 httpd のログデータは、 "common" 形式は7つ、 "combined" 形式は9つのフィールドからなりますが、 "combined" 形式は "common" 形式に2つの追加フィールドがあるだけの違いです。 (1) は、アクセス要求元の ノード の IPアドレス です。 もしもこのIPアドレスが逆引きで FQDN に 名前解決 が可能な場合は、 Webalizer はFQDNで集計を行うことになります。 (2) は、 "identd" と呼ばれるユーザー識別用の デーモン がユーザー側の ホスト で動作している場合に、ユーザーの識別情報が記録されるフィールドです。 |
||||||||
| 要するに、過去の遺物的なフィールドと考えて間違いはありません。 |
実際のところ WAN 空間経由の HTTP 要求でidentdが用いられることはまずありませんので、このフィールドには通常 "-" が記録されます。 |
||||||||
|
|
(3)
には、ユーザー認証が必要なページやディレクトリにアクセスを行う際
例えば、
認証が不要な普通のページへのアクセスの場合は "-" が記録されます。 (4) には、アクセス要求のあった時刻と、 GMT との時差が記録されます。 (5) はアクセス要求元のリクエストの内容です。通常は HTTPメソッド の種類、要求された サーバー 上の URI 、使用された プロトコル の詳細、の順に記録されます。 この例では、「GETメソッドによって、"/_raidbuild/prep_new_disk.html"が、HTTPバージョン1.1で要求された。」ということを意味します。 (6) には 「レスポンスコード」 と呼ばれる、サーバー側の応答と送信の結果を表すコード番号が記録されます。 ちなみに 200 はユーザーの要求に対して正常に処理を行ったことを表します。 一般にステータスコードは、先頭が "2" で始まる場合はリクエストに対して正常に処理、 "3" で始まる場合は、データキャッシュの利用など「ユーザーのリクエストどおりには振舞わなかったが、問題なく要求に応えられたはず。」という処理、 "4" で始まる場合はユーザーからのリクエストに問題がある場合のエラー、 "5" で始まる場合は サーバー 側に問題がある場合のエラーをそれぞれ示すことになります。 (7) にはサーバーからクライアントに送信されたデータ量が バイト で記録されます。 (8) は一般に リファラー と呼ばれる情報で、このリクエストがどこを参照して行われたかということが記録されます。この例では、 |
||||||||
| %E5%... で始まる暗号のような文字列は、Googleが検索を行うときに 「削除 復旧」 という日本語のキーワードを UTF-8 に 文字コードセット を変換したものです。 |
「日本語の Googleの検索ページ から、 "Linux 削除 復旧" というキーワードで検索を行い、その検索結果の一覧からクリックしてこのコンテンツにやってきた。」 ということになるでしょう。リファラーは、このようにどこかのホームページ上のリンクから移動した場合にそのリンク元の情報として記録されます。 ただし、ユーザーがパソコン上のショートカットや「お気に入り」を利用したり、あるいはアドレスバーに直接 URL をタイプしたような場合には "-" が記録されます。 (9) は ユーザーエージェント と呼ばれる、ユーザー側がアクセスに利用した アプリケーション の情報が記録されます。 |
||||||||
| 実は、WindowsXPの本名は WindowsNT var5.1 、 Windows2000 の本名は WindowsNT var5.0 っていいます。知ってました?。 |
この例では Webブラウザ として、 「 WindowsXP 上のインターネットエクスプローラーバージョン6が使われた。」 ということを示しています。 ユーザーエージェントは一般のユーザーが利用するWebブラウザの情報だけではなく、コンテンツの情報を集めに来る検索エンジンの情報収集プログラム(検索ロボット)の情報も記録されます。 ただし、ユーザーエージェントはあくまで自己申告制なので必ずしも正しい情報とは限りませんから注意してください。
|
||||||||
アクセス解析から完全に除外すべきログデータとはApache により収集される ログ データは、過去の痕跡として残されている identd を除けばどれも有用なものばかりです。 ただ、個々のフィールドは重要な情報であっても、例えば「作成中の コンテンツ を作成者自身が確認のための閲覧した結果作成されたログデータ」などは、アクセス解析上は全く無用なものといえます。 |
|||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
それは例えばイベントの観客動員数からその成否を判断する場合、出演者や運営スタッフ、付き合いでチケットを買わされたゲストなどは統計から除外しなければ、本当の人気度を推し量ることはできないのと同じことと考えてください。 Webalizer のレポートの内容は、全体のアクセス数などに関する単純な統計データと、それ以外の細かい解析結果に大別することができます。 このうち、Webalizerの機能で不要なデータを除外可能なのは後者だけですから、統計にも解析にも必要のないログデータは最初から取り除いておく必要があるというわけです。 Apacheは適当に設定を行うことで、複数のログファイルにログデータを振り分けて書き込んだり、不要なログデータを破棄したりすることができますが、その判定の材料は対象となる個々のログデータの内容です。例えば、 |
||||||||
| "crawl(クロール)" 、つまり 検索ロボット のアクセスログを破棄する、という意味合いになります。 |
「ユーザーエージェントのフィールドに"crawl"という文字を含むものは破棄する」 といった処理を行います。 以下、ログデータとして完全にログファイルから除外すべきものと、その判定基準について解説します。 ページ作成者自身のアクセスログ普通 コンテンツ を作成するときは、 FTP などでデータを サーバー に アップロード して最終的な内容の確認を行います。 そのためには必ず Webブラウザ でコンテンツを閲覧することになりますが、当然このアクセスログは何の意味も持ちません。 また、 ブログ のように、原則としてFTPによるコンテンツデータのアップロードを行わず、 HTTP で直接コンテンツを編集するようなスタイルのホームページでは、作成作業そのものがログデータとして大量に記録されることになります。 もしもコンテンツの作成を自宅内の サブネット の ホスト から行っている場合は、アクセス元の IPアドレス 情報が必ず プライベートIPアドレス になるはずですから、これを判定基準にしてログファイルから除外すると良いでしょう。
また、学校や勤め先などからコンテンツの作成を行う場合、もしもそこが固定の
グローバルIPアドレス
ところが、コンテンツの作成場所がインターネットカフェだったりするとIPアドレスは普通非固定になりますからちょっと面倒です。
こういう場合にIPアドレスを判定基準にするには、
もちろんこの方法では、作業中にIPアドレスが変化してしまえば元も子もありませんから、あまり薦められる方法ではありません。 また、自宅のサブネットに DHCPサーバー があり、コンテンツの作成に使うホストにもIPアドレスの自動割当を行っている場合には、DHCPの割り当て範囲すべてに対して除外設定を行う必要がありますが、この場合は同じくDHCPでIPアドレスの割り当てを受けている自宅内のすべてのホストが除外対象になってしまいます。 こういったケースでは、例えば、 のような ユーザーエージェント を任意に変更できるWebブラウザの補助 アプリケーション を使い、そのユーザーエージェントだけをログファイルから除外するという手段もあります。 検索ロボットのアクセスログインターネット空間に コンテンツ を公開していれば、好む好まざるにかかわらず、いずれは 検索ロボット の訪問を受けることになります。 もちろんこれらも ログ ファイルに足跡を残してゆくことになります。 一日に数千あるいは数万ページくらいの閲覧者が訪れるコンテンツであれば、検索ロボットのアクセス数などほんの一部に過ぎないでしょう。 しかしまだ公開して間もない、アクセスの少ないコンテンツの場合、検索ロボットが残してゆくログデータは、全体データ量のかなりの割合を占めることになるでしょうから、アクセス対策を行う際のデータ解析の妨げになってしまいます。 この検索ロボットが残してゆくログデータは、統計にも解析にも意味がないわけですから除外してしまうほうが良いでしょう。 検索ロボットのプログラムは常に同じ ノード から実行されるとは限りませんので、 IPアドレス を振り分けの判定材料することはできません。 しかし有名な検索エンジンの検索ロボットは、それぞれ特有の ユーザーエージェント 名で巡回しますから、これを判定材料にして振り分けを行います。例えば、 Googlebot/2.1; +http://www.google..... ...Google Yahoo! Slurp; http://help.yahoo.com.... ...Yahoo msnbot/0.9 (+http://search.msn.com.... ...MSNサーチ という具合です。 ユーザーエージェントのバージョンなどは将来変わることがあるかもしれませんが、名前が変わることは考えなくて良いでしょう。 またApacheは、ユーザーエージェント名に対して文字列の部分一致で判定を行うことができますから、例えばGoogleの検索ロボットを判定するときは "Googlebot" 、MSNサーチの検索ロボットを判定するときは "msnbot" を指定すれば良いということになります。 検索ロボットは他にもたくさんありますが、利用度の低い検索エンジンの検索ロボットはあまり頻繁には訪問しませんから、とりあえず著名な検索ロボットにだけ注意を払えば問題はないと思います。 アフェリエイトのクローラーのアクセスログこの コンテンツ でも実施していますが、アフェリエイト契約を結んでページ内に広告を貼って小遣い稼ぎをするのは個人でもあまり珍しいことではありません。 特に最近は、 GoogleAdsense のように、添付されるコンテンツの内容に合わせて適切と思われる種類の広告を自動的に表示させる コンテンツマッチ型アフェリエイト の利用者が多くなっています。 こういうスタイルのアフェリエイト契約を結んでいる場合は、当然のことながらその業者の ホスト から クローラー がやってきます。目的はいうまでもなくコンテンツ内容のチェックです。 |
||||||||
|
|
もちろんこれも解析対象のログファイルに記録するのは好ましくありませんから除外しておくべきでしょう。 これは通常の 検索ロボット と基本的には同じ対策、つまり ユーザーエージェント 名で判定して除外することができます。 同じドキュメントルート内の異なるサイトへのアクセスログ
例えば
Apache
のユーザーディレクトリの公開機能
http://www.obenri.com/
以下に、自分のコンテンツとは全く無関係の、
http://www.obenri.com/~hanako/
のような URL が存在することになります。 Apacheは一つのドキュメントルートに対して一つの ログ ファイルを作成するのが普通ですから、何も設定をしなければこれらのコンテンツへのアクセスログは一緒のログファイルに記録されてしまいます。 こういう場合に振り分けを行うには、アクセス元の ノード や ユーザーエージェント などを判定材料にすることはできませんので、 サーバー 上のディレクトリ位置、つまりユーザーが要求する URI によって振り分けを行う必要があります。 Webメールの利用に伴うアクセスログ
SquirrelMail
これは普通 コンテンツ へのアクセスとみなすことはできませんから、当然除外しておく必要があります。
このコンテンツで紹介しているSquirrelMailの場合には、すべての
HTTP
アクセスは
従ってこの場合は上で説明したユーザーディレクトリの利用の場合と同様に、 サーバー 上のディレクトリ位置、つまりユーザーが要求する URI によって振り分けを行うことになります。 Wealizer自身へのアクセスログ灯台下暗しというべきかもしれませんが、 Webalizer のアクセス解析結果の閲覧も立派な httpd へのアクセスですから、きっちり ログ ファイルに記録されることになります。 |
||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
もしも解析結果を公開して、そのアクセス数を知りたいという場合はそのままでも構いませんが、自分以外のクライアントに閲覧許可を与えない場合は コンテンツ へのアクセスとみなすことはできませんので、当然除外しておく必要があります。 この場合 HTTP アクセスは、例えばディレクトリ "/var/www/usage/" に対して行われます。 従って上で説明したユーザーディレクトリの利用の場合と同様に、 サーバー 上のディレクトリ位置、つまりユーザーが要求する URI によって振り分けを行うことになります。 ところがもしも、Webalizerのアクセス解析結果を閲覧する人がコンテンツ作成者本人だけである場合で、その接続元の ノード や ユーザーエージェント に対してログデータの除外処理を行う場合には、Webalizerのアクセス解析結果へのアクセスも同時に除外されてしまいます。 こういう場合は特に何か設定を行う必要はありません。 振り分けが必要なその他のアクセスログ
例えばこのコンテンツでも参加している
「自宅サーバーWebRing
その他にも、外部の ホスト から何らかの監視やチェックを受けるようなサービスを利用している場合には、それらのアクセスを担うユーザーエージェントを調べ、除外設定を行う必要があるかもしれません。
|
||||||||
ユーザーエージェントを調べる方法検索ロボット などの ログ データを ユーザーエージェント 名を元に振り分けを行う場合、あたりまえのことですがその名前をきちんと把握しておく必要があります。 しかしそれらのユーザーエージェント名が公式にアナウンスされることは比較的稀ですから、必要に応じて自分で調べなくてはなりません。 著名な検索ロボットのユーザーエージェント名の場合は、例えば、 「ホームページのアクセスアップ」 、あるいは 「SEO対策」 などと銘打った本や雑誌に掲載されている場合もありますし、インターネットから 「ユーザーエージェント」 、 「クローラー」 などのキーワードで検索すれば比較的容易に探し出すことができます。 ただし、ユーザーエージェント名は検索エンジンサイトなどが独自に命名したものですから、現在使われているものとは既に違っているかもしれませんから注意してください。 とはいえ、大手のサイトが巡回させている検索ロボットのユーザーエージェント名がコロコロ変わっていては、多くの利用者から嫌われてしまうでしょう。 というわけで、大手に限っていえば、検索ロボットのユーザーエージェント名がある日突然変わってしまうことはまずあり得ないと思って良いのではないでしょうか。 検索ロボットのユーザーエージェント名を正確に調べる一番確実な方法は、実際に Apache の ログ ファイルを見てみることです。 通常検索ロボットのユーザーエージェント名の中には、それが検索ロボットであることを示す文字列、例えば、 "robot" 、 "bot" 、 "crawl" あるいはその先頭の一文字または全部の文字が大文字になっているものが含まれている場合がほとんどです。 そこで、 シェル プロンプト から cat コマンド と grep コマンドを使って実際に調べてみましょう。
まず、
サブネット
内の適当な
クライアント機
から
SSHクライアント
で
構築中のLinuxサーバー
に
ログイン
します
それから su コマンド で アカウント を "root" に変更し、 cd コマンドでApacheのログファイルが格納されている "/var/log/httpd" に移動して以下のようにコマンドを実行してみます。
ここでは "msnbot" と "Googlebot" だけが抽出されていますが、実際にはもっと見つかるかもしれません。 検索ロボットのユーザーエージェントが見つかったら、その名前を元に次のパートで具体的なログデータの除外設定を行いますので控えておきましょう。
|






|
|
Webalizerの基本設定
<<Previous
|
Next>>
Apacheでログを振り分ける
|
| このサイトは既に更新を終了していますが、今のところ店じまいの予定はありません。 リンクフリー ですので、趣味や勉強のためでしたら、引用、転用、コピー、朗読、その他OKです。このサイトへのリンクについては こちら をご覧ください。 |

|
| ”Linux”は、Linus Torvalds 氏の各国における登録商標です。”Red Hat”及びRed Hatのロゴおよび Red Hat をベースとしたすべての商標とロゴは、各国におけるRed Hat, Inc. 社の商標または登録商標です。その他のプログラム名、システム名、製品名などは各メーカー、ベンダの各国における登録商標又は商標です。 |

|