
|
|
|
webalizerでアクセス解析
|
Webアクセス解析とはWebalizer日本語版の導入Webalizerの基本設定httpdログの構造を理解するApacheでログを振り分ける検索文字列の日本語化統計データの見方について解析データの最適化と分析法解析スケジュールの設定デフォルト以外のアクセス解析 |
解析データの最適化と分析法Webalizer の統計データから得られる情報は要するに「アクセスの分量」ですから、「どのくらい増えたか、減ったか。」という アクセスアップ対策の結果 に過ぎません。 アクセスアップ対策に必要なのは、 コンテンツ 内のどのページのアクセスが多いか」 あるいは 「どのサイトからアクセスされているのか」 などの解析データです。 これらの解析結果のリポートは、 クライアント がどういう情報を欲しがっているか、あるいはどういう方法で訪問してくるのか、といった「マーケットリサーチ」的なものですので、より良いコンテンツ作りには欠かせないものでしょう。 Webalizerはそういったアクセス対策に必要な解析結果もリポートしてくれますが、 デフォルト のままでは邪魔になるデータも含まれてしまうことが多いので、これは自分で設定ファイルの内容を修正して最適化する必要があるでしょう。 また、以下に説明する各リポートは基本的に「順位」で行われ、それぞれに デフォルト で表示される順位の数が決められています。 これはWebalizerの設定ファイル "/etc/webalizer.conf" の 302〜312 行目の、
の該当する設定のコメント記号 "#" をはずし、数値を変更することで増減することができます。 この中のどの設定がどのリポートに該当するものかは、以下の説明の中で行っていきます。
|
|||||||||
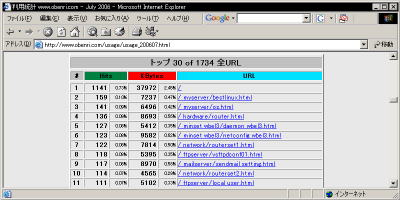
URLの"Hits"数のリポート |
||||||||||
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
 お便利サーバー.com
検索ロボット
お便利サーバー.com
検索ロボット
|
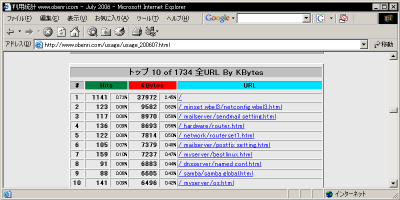
これらのリポートはそれぞれ30位、10位まで表示されていますが、このページの冒頭で説明した、 "TopURLs" 、 "TopKURLs" ディテクティブ で適宜増減することができます。 集計の基準が "Hits" ですので精度は高くないはずですが、全体的な「人気のあるページ」の傾向はこれでつかめるでしょう。 ところで、それぞれのデータのタイトルの "1734全URL..." というのは、 "Hits" のあったすべてのファイルの種類の合計です。 つまり HTML ファイルだけではなく、動的に生成されたページや画像データへのアクセスもひとつのURLとしてカウントされますからこれは想像よりもかなり大きな数字になるはずです。 さて、例えば「お便利サーバー.com」の場合、すべてのページに同じロゴが多用されていますから、実は最も多くカウントされているURLは、 
"/_image/next01ss.gif" です。にも係わらずこれらの表に表示されないのは、設定ファイル "/etc/webalizer.conf" への記述で、 "*.gif" などの「一覧に表示しても意味のない種類のURL」が一覧から除外されているからです。その設定は "HideURL" ディテクティブで行います。 HideURL〜URLの集計結果からデータを除外(386行目〜)Webalizer の URL の集計結果から、特定のファイル名を除外する ディレクティブ です。 デフォルト では、
と、ごく一般的に使われる画像ファイルが除外設定されています。 もちろん ワイルドカード を使わずに直接 パス とファイル名を指定することもできます。 ただ実際には、除外したいファイルの種類はこれだけではないはずです。 例えば画像ファイルに "*.jpeg" というファイル名を使っていたり、外部スタールシートファイルや Javaスクリプト ファイルなどの集計しても仕方がないファイルもあるはずです。 例えば「お便利サーバー.com」の解析では、このディレクティブには次のような追加設定をしています。
この設定は、運営中のコンテンツのファイルの種類に合わせて適宜行ってください。
|
|||||||||
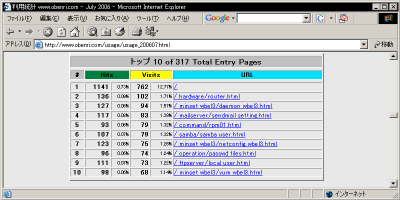
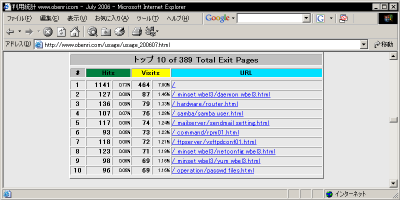
訪問の「入口ページ」と「出口ページ」のリポート
解析対象の
コンテンツ
内で、
クライアント
が訪問してきた「入口ページ」と、最後に閲覧していった「出口ページ」を、
"Visits"
これらのリポートはそれぞれ10位まで表示されていますが、このページの冒頭で説明した、 "TopEntry" 、 "TopExit" ディテクティブ で適宜増減することができます。
これらのリポートは、
"Pages"
の数値と同じく、
"PageType"
ディレクティブ
検索ロボット 中心の現在のインターネット環境においては、一般的にはそのコンテンツのトップページが最も露出度が高くなる傾向にあるため、「入口ページ」はほぼ間違いなく "/" が最も多くなるはずです。 |
||||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
従って、トップページ以外の特定のページが「入口ページ」として高い割合を示す場合は、 ・そのページの内容が検索ロボットに「引っかかりやすい」構成になっている。 ・そのページの有用性が高く、外部のサイトからリンクされている数やブックマークされている数が多い。 などの理由が考えられますので、詳しく研究して他のページのアクセスアップに結び付けたいところです。 また、訪問者がそのコンテンツに興味を持ってくれた場合には、少なくとも数ページ程度は閲覧して帰ってゆくはずですが、わざわざトップページに戻ってから立ち去ることはあまりありません。 従って「出口ページ」に占めるトップページの割合が多いときは、「トップページを見たが興味がなかったのでそのまま立ち去った」というケースが多いことを示している可能性が高いといえます。 もちろん、こういった分析は対象となるコンテンツの性格にもよりますから、こういった一般論だけを鵜呑みにせず、自分なりの分析を行うようにしなければいけないのは言うまでもありません。
|
|||||||||
アクセス元のノードのリポート
特定の
ノード
からのアクセスについて、
"Hits"
これらのリポートはそれぞれ30位、10位まで表示されていますが、このページの冒頭で説明した、 "TopSites" 、 "TopKSites" ディテクティブ で適宜増減することができます。 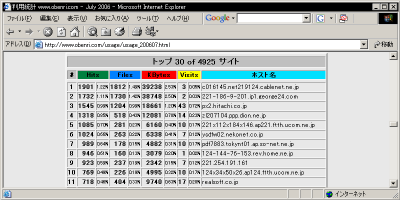
特定のノードからの"Hits"数トップ30 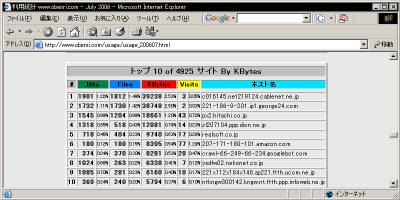
特定のノードからの要求"KBytes"数トップ10 これらのデータは、もともとは大部分がアクセス元の IPアドレス として ログ データに記録されたものです しかし Webalizer はアクセス解析の際、逆引きの 名前解決 が可能なIPアドレスについては FQDN として集計し、これらの集計表に記録するようになっています。
これらのデータからは、例えばアクセスの多い
ドメイン名
の
団体種別
また、 検索ロボット の中には ユーザーエージェント 名では判断できなくても、FQDNの サブドメイン に "crawl" などが使われていることがあります。 つまりこの情報は、検索ロボットの足跡を Apache のログデータから除外するときの判断材料にすることにもできるわけです。
さて、Apacheによるログデータの振り分け
しかしログデータの振り分けを行っていない場合には、例えば LAN 内からのアクセスなども記録されてしまうことになりますから、これは表示データから除外するほうが望ましいでしょう。その設定は "HideSite" ディレクティブ で行います。 HideSite〜ノードの集計結果からデータを除外(376行目〜)Webalizer の ノード 毎の集計結果から、特定のノードを除外する ディレクティブ です。 デフォルト では、
と、一般的な設定例とコメントアウトされた "localhost" だけが記述され、有効になっている設定はありません。 例えば、
と設定すると、 構築中のLinuxサーバー を含む LAN 内のすべての ホスト からのアクセスがノード毎の集計結果の一覧から除外されるようになります。
|
||||||||||
リファラーのリポート
特定の
リファラー
からのアクセスについて、
"Hits"
このリポートは30位まで表示されていますが、このページの冒頭で説明した、 "TopReferrers" ディテクティブ で適宜増減することができます。 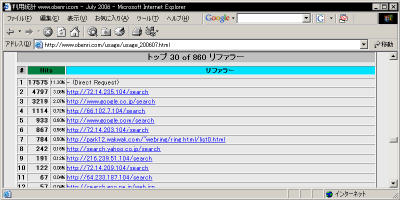
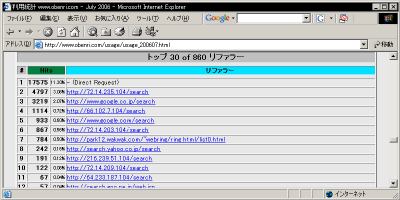
特定のリファラーからのHits数トップ30 このデータは、 ログ データに記録されているリファラーを集計したものです。 検索ページやリンクページからのジャンプではなく、クライアントが直接アドレスバーに URL をタイプしたりブックマークを使ったりするとリファラーは記録されませんから、 "- (Direct Request)" として集計されます。 このデータを解析することによって、 クライアント がどういう手段を使ってこの コンテンツ に訪問してくるケースが多いのかがわかりますから、アクセスアップ対策の中では最も重要なデータといえるでしょう。 ただし、 デフォルト の設定のまま Webalizer を実行すると、おそらくこういう「有用な」情報にはならず、コンテンツ内の URL ばかりが上位にランクされるだけだと思われます。 例えば、クライアントが
"http://www.obenri.com/_myserver/bestlinux.html"
のページを開いたとします。このページには色々な画像ファイルが貼ってありますが、これらの画像ファイルは、
"http://www.obenri.com/_myserver/bestlinux.html"
をリファラーとして呼び出されます。 従ってもしもこのページに20個の画像ファイルが貼ってあり、それらの画像ファイルが "/var/www/html" 以下、つまりWebalizerのアクセス解析対象のディレクトリの中に入っていると、 「"http://www.obenri.com/_myserver/bestlinux.html"はリファラーとして20カウント」 と計算されてしまうことになります。 また、
"http://www.obenri.com/_myserver/bestlinux.html"...
(1)
上のリンクボタンから
"http://www.obenri.com/_myserver/getlinux.html"...
(2)
に移動したとします。 これはごく当たり前に行われる「サイト内移動」ですが、この場合、 (2) へのアクセスに関しては (1) がリファラーとして記録されます。 |
||||||||||
|
|
もちろんアクセス解析では、「クライアントがサイト内でどういう移動をしたのか」、という情報は無視できませんが、こういう「サイト内移動」のデータを表示してしてまうと結果としてもっと重要な「サイト外からの移動」のデータがそれに埋もれてしまうことにもなりかねません。 そこでこのような「サイト内部での参照によって発生するリファラー情報」は、集計データから省くほうが望ましいでしょう。 その設定は "HideReferrer" ディレクティブ で行います。 上に示したリファラーの集計例は、以下のような設定でサイト内の参照を除外しています。 HideReferrer〜特定のリファラーの集計から除外(380行目〜)Webalizer の リファラー 毎の集計結果から、特定のリファラーを除外する ディレクティブ です。 デフォルト では、
と、一般的な設定例とコメントアウトされた "Direct Request" だけが記述され、有効になっている設定はありません。 |
|||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
例えば、
と設定すると、 ログ データ中で "obenri.com" という文字列がリファラーに含まれる場合、リファラーの集計結果の一覧から除外されます。
|
|||||||||
検索文字列のリポート |
||||||||||
|
もしもここに表示されている検索文字列が「文字化け」している場合は、
を参考に、きちんと日本語表示が出来るようにしましょう。
|
このリポートは20位まで表示されていますが、このページの冒頭で説明した、 "TopSearch" ディテクティブ で適宜増減することができます。 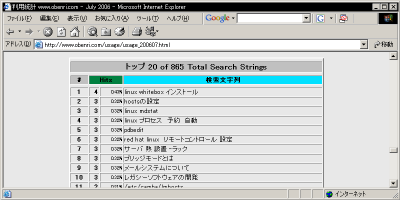
使用された検索文字列トップ20 ここにリストされる検索文字列はリファラーに記録されているものですから、 「クライアントが実際にこの文字列で検索を行い、表示されたサイトの一覧からクリックして訪問してきた数。」 という非常に具体的なデータです。 一般に検索エンジンを利用してサイト検索を行っても、表示される順位が低ければクリックはおろかまずクライアントの目にとまることはありません。 従ってここに表示される検索文字列はかなり上位でこのコンテンツをリストすることのできる優良な検索文字列といえます。 |
|||||||||
|
お便利サーバー.com
では、2006年5月まではこの数字は一桁でしたが、その翌月から一気に1,000を超えるようになりました。
そのくらい劇的に変わるので、とってもうれしい数字です。 |
開設して間もないコンテンツでは、なかなかこのリストに検索文字列が載ることはありませんが、アクセスアップ対策がうまく行きはじめるとこのリストが急に賑やかになってきます。 注目すべきは具体的な文字列の内容だけではなく、このリストのタイトル、
トップ 20 of 865 Total Search Strings
の 赤字 で表した部分の 検索文字列の総数 で、コンテンツの露出が始まるとこれが急速に大きくなります。 現在のインターネット環境では、検索エンジンを利用して目的のサイトを探すことが一般的になっていますから、この数字が月ごとに上昇しているときは「人気上昇中」、変化がないときは「停滞気味」、下降し始めたら「他のサイトに抜かれ気味」ということを意味するでしょう。 ただ、このデータは デフォルト のままだとデータの取りこぼしが起きていますので、 "SearchEngine" ディレクティブ を修正する必要があります。 SearchEngine〜検索エンジンのクエリの設定(517行目〜)
Webalizer
が
リファラー
データの中から「検索文字列」に相当する部分を抜き出す場合、例えば、
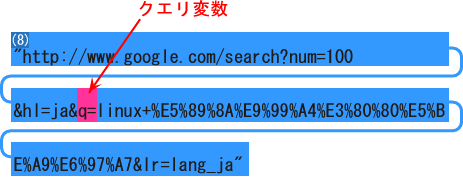
ログデータ中のリファラーの例 の赤で示しているクエリ変数(問い合わせのための変数) "q=" 以降を検索文字列と判定します。 ところがこのクエリ変数は検索エンジンの種類によって異なりますから、検索エンジンごとに明示的に指定しなければなりません。 その設定を行うのが "SearchEngine" ディレクティブ です。 一般書式は SearchEngine [リファラーに含まれる文字列] [クエリ変数] です。 デフォルト では、 |
|||||||||
|
実は、
"hotbot.com"
のクエリ変数は
"query="、
"msn.com"
のクエリ変数は
"q="、
が正解です。こんな具合にこのリストは結構間違いがあります。
日本語のコンテンツが対象の場合は、 "msn.com" のクエリ変数だけは修正しておきましょう。 |
となっていて、一般的に利用される ".com" ドメイン名の検索エンジンがリストアップされています。 ただ、日本国内で一般的に用いられる検索エンジンのドメイン名は ".jp" が多いですし、Googleのように逆引きの 名前解決 ができない検索エンジンサーバーもありますから、このままではかなりの「データの取りこぼし」が起こってしまいます。 そこで、前に説明した 「リファラーのリポート」 を上位のほうから順にクリックしてみて、それが検索エンジンであれば上位から10〜20番目くらいまでを追加記述しておけば良いでしょう。 |
|||||||||
| 検索に全角文字を使うと UTF-8 に 文字セット が変換され、アドレスバーのどこにクエリ変数があるのか判らなくなってしまいますので注意してください。 |
その検索エンジンのクエリ変数がわからないときは、実際に "半角英文字" の適当な語句で検索をかけてみれば、クエリ変数は Webブラウザ のアドレスバーに、
.......[クエリ変数]=[検索を行った文字列]
という書式で表示されますので調べてみてください。 |
|||||||||
|
追加した検索エンジンで、
"http://[IPアドレス]/search"
となっているものは、実はGoogleの検索エンジンです。
その意味についてはこのページの最後に "グループオプションについて" で解説します。 |
もちろん、これではすべての検索エンジンからの情報を得ることはできませんが、検索文字列は「大まかな傾向」さえ判れば良いのでこれで充分なはずです。 |
|||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
ただ検索エンジンの利用頻度や名前、IPアドレス、クエリ変数などは恒久的なものではありませんので、ときどき 「リファラーのリポート」 とこの設定内容を照合して、設定内容を修正しなければならないことを忘れないでください。
|
|||||||||
認証したユーザー数のリポート
Apache
でユーザー認証が必要なディレクトリを設定している場合に
要は
ログ
データの「ユーザー名のフィールド」
このリポートは20位まで表示されますが、このページの冒頭で説明した、 "TopUsers" ディテクティブ で適宜増減することができます。 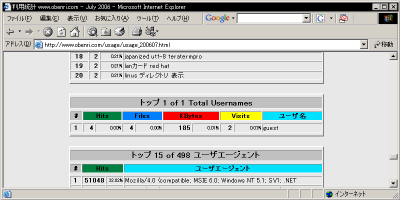
認証されたユーザー名トップ20
上のリストはこの「お便利サーバー.com」の
コンテンツ
のものですので、
コンテンツ中に認証が必要なディレクトリを作成し、利用者に対して個別にユーザー名を与えている場合には、このリストを参照することでその利用頻度を知ることができるようになります。
|
||||||||||
ユーザーエージェント数のリポートログ ファイルに記録されている ユーザーエージェント の集計です。 このリポートは15位まで表示されますが、このページの冒頭で説明した、 "TopAgents" ディテクティブ で適宜増減することができます。 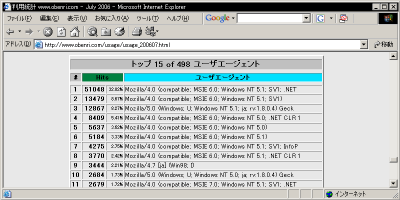
ユーザーエージェント名トップ15
もしも「不要なログデータの振り分け」
要するに、このコンテンツを訪問している クライアント の OS とWebブラウザの種類が多い順に表示されているわけです。 もちろん、それだけではほとんど利用価値のないリストなのですが、例えばここに「検索ロボット臭い」ユーザーエージェントが表示されるようでしたら、その名前を元にログデータの除外処理を行うことができます。 そういう意味においては「利用価値のない」リストではないということになります。
|
||||||||||
国別アクセス数のリポート
集計対象の識別データはこのページの前半で説明した
"アクセス元のノードのリポート"
と同じく
IPアドレス
または
FQDN
ですが、そのFQDNの中の
ドメイン名
の末尾から、「ドメイン名の管轄の国」を割り出し
このリポートは30位まで表示されますが、このページの冒頭で説明した、 "TopCountries" ディテクティブ で適宜増減することができます。 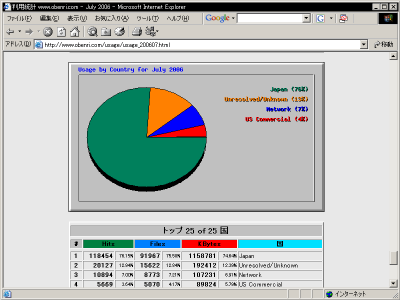
国別のアクセス数トップ30 日本語のコンテンツを運営している場合は大部分が ".jp" からアクセスしますので、このデータは日本からのアクセスが大部分を占めます。 ただ ".com" や ".tv" のようにドメイン名によっては他の国のものでありながら日本で使われることが多いものがあります。 それらのドメイン名は日本の WAN 上で逆引きの 名前解決 結果に使われているケースも多いので、こういう場合は日本国内からのアクセスであっても海外からのアクセスとして集計されることになるでしょう。 という具合にこの国別のアクセスリポートは「必ずしも正いものではない」ので、参考程度にとどめておくのがよいでしょう。
|
||||||||||
グループオプションについて例えば リファラー のリポートをみると、 "http://[ IPアドレス ]/search" というリファラーが非常に多いことにお気づきでしょうか。 実はこれらのリファラーはほとんどが Google の検索ページを表しています。 Googleの サーバー は一台のサーバーへの負担を減らすため、世界中で常時100台以上稼動させていて分散処理を行わせているため、こういったリストになってしまう訳です。 |
||||||||||
|
|
つまりGoogle検索経由からのアクセス数を知りたいと思ったら、これらの数をすべて合計しなければならないことなり、とても面倒です。 Webalizer はこういう問題に対処できるように、 「共通の文字列を持つデータはグループとして集計して結果を表示する」 という グループオプション 機能を持っています。 その設定例は、 "/etc/webalizer.conf" の 402〜427 行目にありますが、設定可能な項目は以下のとおりです。
例えば、
のように設定を行うと、同じ検索エンジンでありながら異なるリファラー名を持つものの "Hits" を合計し、このページで説明した、 "リファラーのリポート" の中に、リファラー名 "Yahoo!" 及び "GoogleSearch" でリストさせることができます。 ただしこの設定だけでは、グループ化された個々のリファラーはそのままリストに表示され、 「二重計上」 になってしまいますから、実際には、
のように "HideReferrer" ディテクティブ を併用して、グループ化したリファラーは個別に表示させないほうが誤解がなくて良いでしょう。 |
|||||||||
|
この
お便利サーバー.com
のアクセス解析結果を公開中ですのでご覧ください。
お便利サーバー.com
検索ロボット
|
ここではリファラーを例にグループ化の説明をしましたが、それ以外のデータについても方法は同じですから、必要に応じて利用してください。 グループ化されて集計されたデータは、通常のデータと区別がつきやすいように、濃いグレーのバックに太文字でリストされます。 これを通常のデータと同じ表示にするディレクティブはありますが、紛らわしくなるだけですのでデフォルトのまま使用しましょう。 ところで、新たにグループオプションの設定を行った場合、その集計が行われるのは、前回Webalizerが実行された後に収集されたログデータに限られます。 つまり、既にリストに表示されているデータが集められてグループ集計が行われるわけではないことに注意してください。 一方で、データを非表示にする "Hide*" ディレクティブは、設定を行ってWebalizerを実行すると、その月いっぱいまで遡って非表示になります。 ということは例えば上のような "Group*" と "Hide*" を組み合わせた設定を月の半ばで行ってしまうと、それまでにリストされていたデータは非表示になり、新たにグループ化して収集を始めたデータはゼロからのスタートとなって、一時的に「リストからほとんどのデータが消える」という状況になってしまいます。 従って、このグループ化の設定は可能な限り月の変わり目に行うのが望ましいといえます。
|

|
|
統計データの見方について
<<Previous
|
Next>>
解析スケジュールの設定
|
| このサイトは既に更新を終了していますが、今のところ店じまいの予定はありません。 リンクフリー ですので、趣味や勉強のためでしたら、引用、転用、コピー、朗読、その他OKです。このサイトへのリンクについては こちら をご覧ください。 |

|
| ”Linux”は、Linus Torvalds 氏の各国における登録商標です。”Red Hat”及びRed Hatのロゴおよび Red Hat をベースとしたすべての商標とロゴは、各国におけるRed Hat, Inc. 社の商標または登録商標です。その他のプログラム名、システム名、製品名などは各メーカー、ベンダの各国における登録商標又は商標です。 |

|