- Home ›
- Ruby正規表現の使い方 ›
- Ruby正規表現における日本語の扱い ›
- HERE
文字コードによるメタ文字(.)のマッチの違い
広告
メタ文字(.)は任意の1文字にマッチしますが、文字コードが「NONE(ASCII)」以外の場合にはメタ文字(.)は全角文字の1文字にマッチするようになります。
/a.b/u
上記のような正規表現オブジェクトを作成した場合、「aob」や「atb」などだけではなく「a山b」や「a本b」などにもマッチするようになります。
逆に文字コードに「NONE(ASCII)」を指定した場合には、全角文字もバイト単位で扱われます。
/a.b/n
上記のような正規表現オブジェクトを作成した場合、「aob」や「atb」にはマッチしますが「a山b」や「a本b」にはマッチしません。(文字列がUTF-8で記述されていた場合は1文字が3バイトなので「a本b」は「/a...b/n」にマッチします)。
このようにマルチバイトを認識できる文字コード(u, s, e)を指定した場合には、メタ文字(.)はアルファベット1文字だけではなく全角文字の1文字にもマッチします。
サンプルプログラム
では簡単なプログラムで確認して見ます。
#! ruby -Ku
require "kconv"
def check1(str)
if /a.b/u =~ str then
print(Kconv.tosjis("○" + str + "¥n"))
else
print(Kconv.tosjis("×" + str + "¥n"))
end
end
def check2(str)
if /a.b/n =~ str then
print(Kconv.tosjis("○" + str + "¥n"))
else
print(Kconv.tosjis("×" + str + "¥n"))
end
end
print(Kconv.tosjis("/a.b/u にマッチするかどうか¥n¥n"))
check1("aob")
check1("a計b")
check1("aおb")
print("¥n")
print(Kconv.tosjis("/a.b/n にマッチするかどうか¥n¥n"))
check2("aob")
check2("a計b")
check2("aおb")
上記のプログラムを「test2-1.rb」として保存します。文字コードはUTF-8です。そして下記のように実行して下さい。
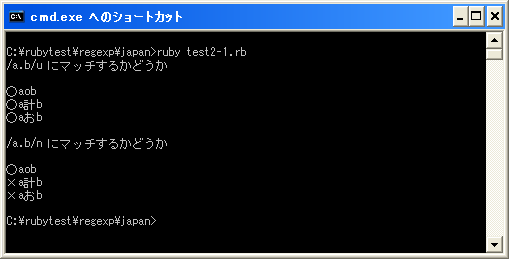
今回は「/u」をあえて記述していますが、もともと「$KCODE」にUTF-8が設定されていますので実際には文字コードの指定は必要ありません。
( Written by Tatsuo Ikura )
