テーブルにデータを登録するには以下の2通りの方法があります。
- SQL文を実行する
- データビューを使用する
ひとつ目のSQL文を実行する方法はpsqlコマンドによりデータベースへログインするなどして行います。ふたつ目のデータビューを使用する方法はpgAdminを使用して登録することになります。
ここでは後者のデータビューを使用して登録する手順を見ていきます。
データビューによるデータ登録
pgAdminの機能であるデータビューを使用すれば、データの登録・削除・参照をGUIベースで行えます。
※ただし、登録に関しては、主キーが設定されている、もしくはテーブル作成時に「OIDを持つ」にチェックを入れている必要があり、いずれの条件も満たしていない場合は、参照のみとなり、登録はできません。
早速、データビューを使用してデータを登録してみます。
pgAdminを起動したら左ペインのオブジェクトブラウザのツリーから「staff」テーブルを右クリックし、コンテキストメニューから「データビュー」-「全ての列を表示」をクリックします。(以下のスクリーンショットではテーブル名が「sampleDB」となっていますが、「staff」テーブルに読み替えてください。)
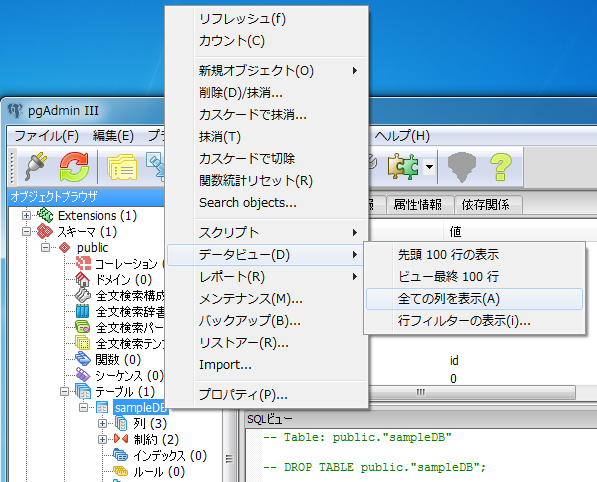
すると、以下のダイアログボックスが表示されます。
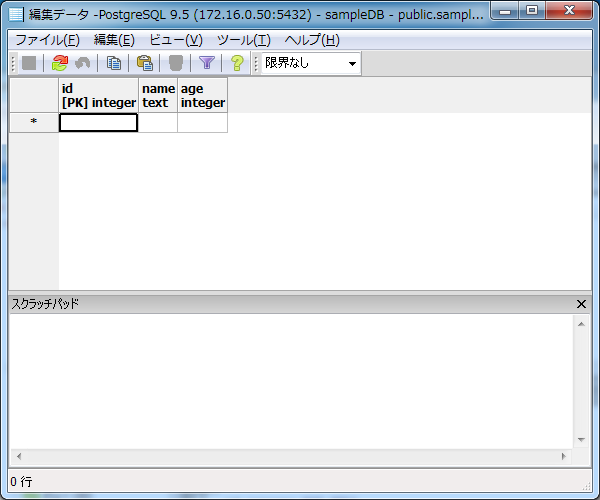
ここに、1行(レコード)ずつ、適当なデータを入力してみてください。

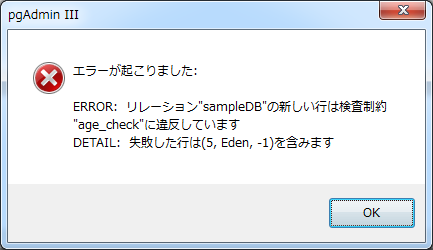
各列にデータを入力し、Enterキーを押下すれば、その時点でデータは登録されます。その際、テーブル作成時に取り決めた制約を守っている必要があります。例えば、「age」列に0より小さな値を入力した場合、制約違反となり以下のようなエラーが出力されます。
データビューによるデータ削除
続いて、登録したデータを削除してみましょう。今回は5行目のレコードを削除してみます。
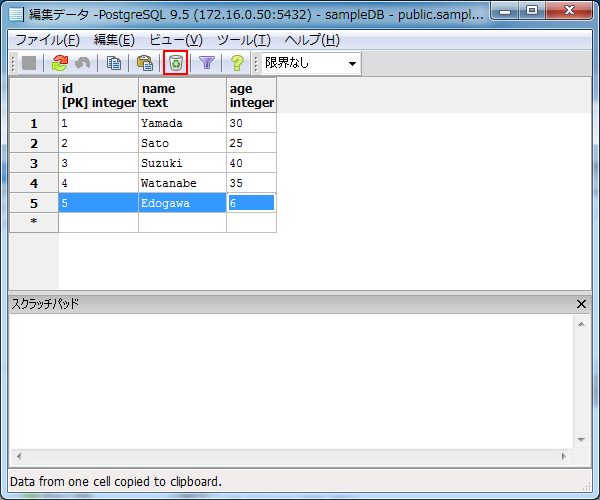
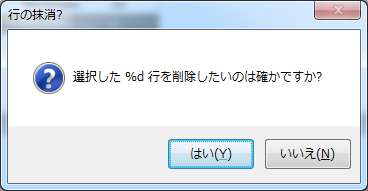
6歳ではまだ労働できないので「staff」テーブルから削除します。当該行を選択した状態で、画面上部のゴミ箱アイコンをクリックします。
すると、以下のような確認ダイアログが表示されるため「はい」ボタンを押下します。
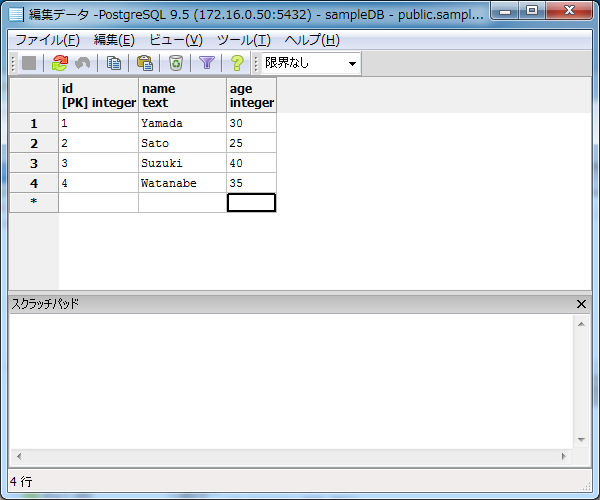
行が削除されているのが確認できます。
データビューによるデータ検索
データベースの主目的はデータ検索をすばやく行うことです。次に、データビューを使用して「staff」テーブルに格納されているデータを検索してみましょう。
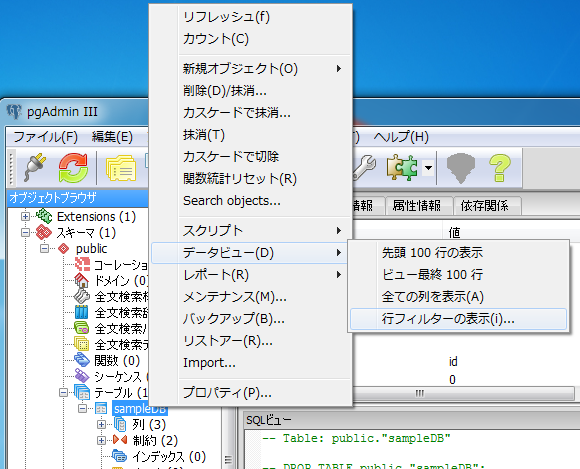
左ペインのオブジェクトブラウザのツリーから「staff」テーブルを右クリックし、コンテキストメニューから「データビュー」-「行フィルターの表示」をクリックします。
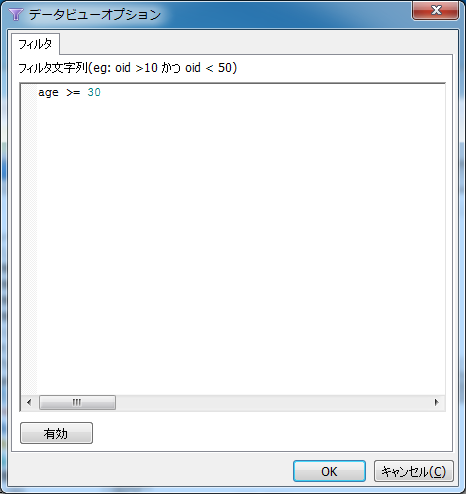
以下のようなダイアログボックスが表示されます。「フィルタ文字列」テキストボックスに「age >= 30」と入力して「OK」ボタンを押下します。
すると、以下のように「age」(年齢)が30歳以上のスタッフのレコードのみが表示されます。
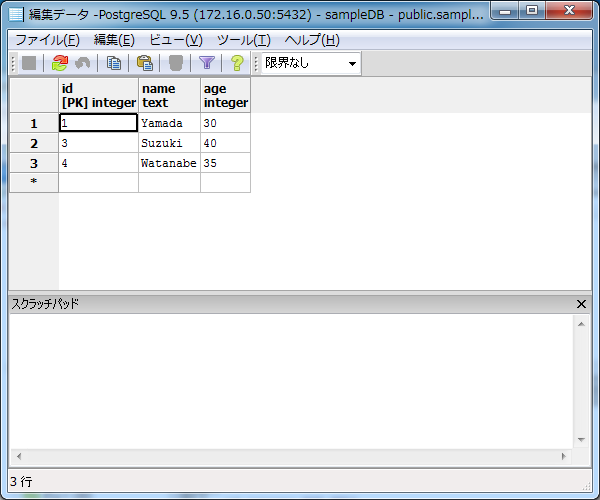
このように条件式を入力し、その条件を満たすデータのみをデータビューに表示させることができます。
スクリプトによるデータ検索
pgAdminからSQL文を直接発行してデータ検索を行うこともできます。
左ペインのオブジェクトブラウザのツリーから「staff」テーブルを右クリックし、コンテキストメニューから「スクリプト」-「SELECTスクリプト」をクリックします。
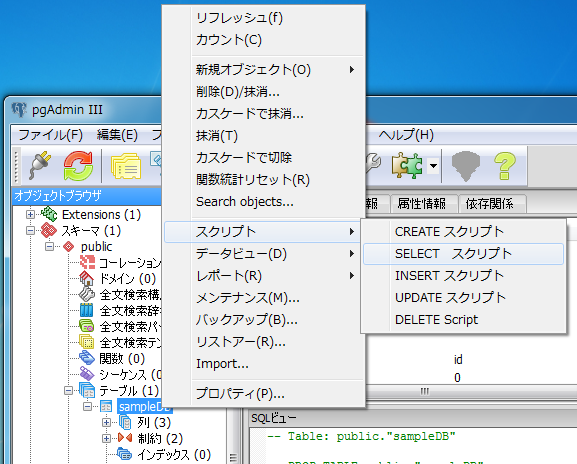
以下のようなダイアログボックスが表示されます。「SQLエディタ」に任意のSQL文を入力し、画面上部の実行アイコンをクリックすれば、画面下部の出力ビューに結果が表示されます。
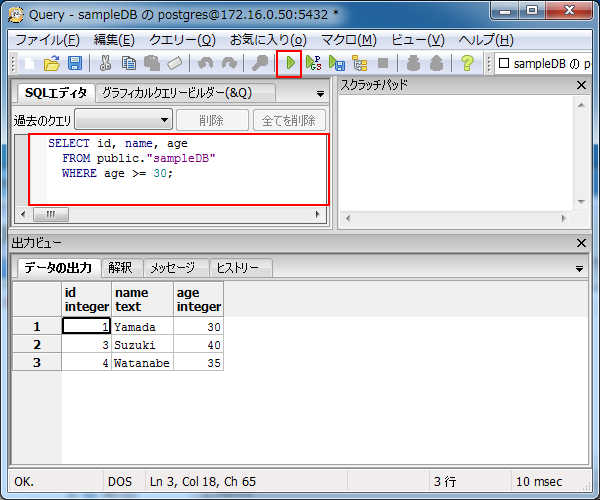
SQLに慣れてる場合は、こちらの方法の方が便利かもしれません。
]]>